
This guide explains how to enable GPU pass-through using an Nvidia GPU and how to install Ollama.
Qubes OS does not have built-in AI features. However, you can integrate AI functionality into common productivity applications by running local language models (LLMs) on your system.
There are advantages and disadvantages to this approach. On the positive side, it allows you to run the AI locally on your hardware, giving you full control over your data. The downside is that it requires significant system resources, especially for larger models. While you can technically run an LLM without GPU acceleration, performance will be poor, limiting model size and drastically slowing down processing times.
GPU pass-through for AI integration is simpler to configure compared to setups used for gaming. In this scenario, you won’t need a video output from the GPU, eliminating the need to configure xorg or use a dedicated display for the GPU. This also means that a qube designed exclusively for AI integration cannot be used for gaming.
If you also want to play video games, see this guide.
Before proceeding with GPU pass-through, you must first hide the GPU from dom0. See this guide for hiding the GPU.
Setting up qube
Create a standalone qube, don’t use a minimal template unless you are familiar with using minimal templates.
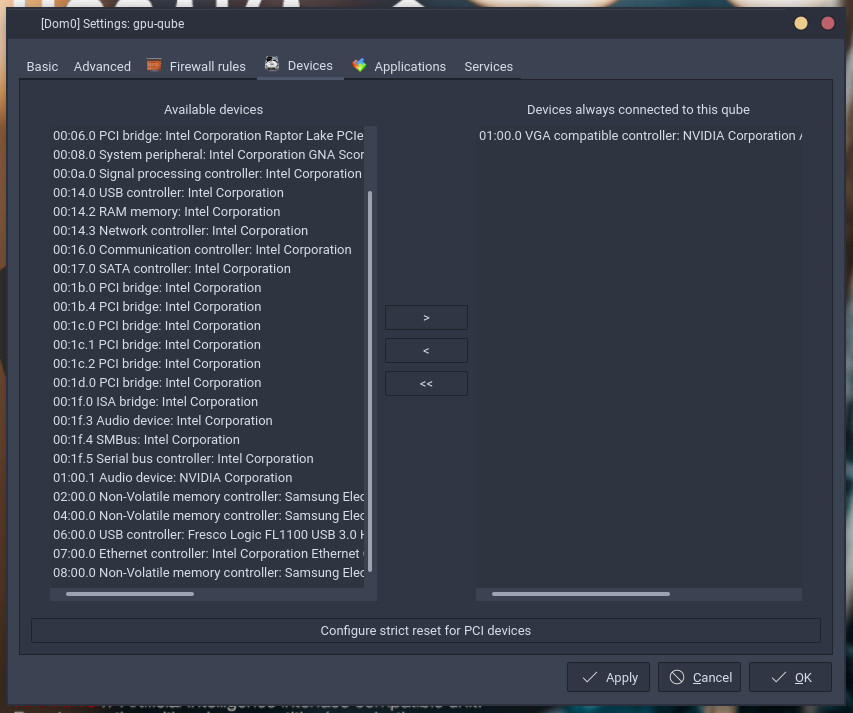
In the qube settings disable memory balancing, set the kernel to provided by qube, and the mode to HVM.

In the Device tab, add the GPU you want passed to the qube.
Install software requirements
sudo apt install software-properties-common apt-transport-https curl git
Install Nvidia CUDA driver
curl -fsSL https://developer.download.nvidia.com/compute/cuda/repos/debian12/x86_64/cuda-keyring_1.1-1_all.deb -o cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo add-apt-repository contrib
sudo apt update
sudo apt install nvidia-kernel-dkms cuda-drivers
At this point, reboot the system and run nvidia-smi, to confirm the GPU is available, and ready for use.
Install docker
sudo curl -fsSL https://download.docker.com/linux/debian/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/debian \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt update
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
sudo usermod -aG docker user
Exit the shell and log back in, to apply user permissions.
Install Ollama
curl -fsSL https://ollama.com/install.sh | sh
Now Ollama should be installed and ready for use, test it by running a model.
ollama run llama3
Allowing other qubes to use Ollama
Using qubes.ConnectTCP is a good way to allow other qubes to access the Ollama qube. The two main advantages are that you can run Ollama offline, and because connection is done though a local port, it makes integration easier.
In dom0, the file /etc/qubes/policy.d/30-user-networking.policy will control what qubes can Ollama.
qubes.ConnectTCP +11434 browser-qube @default allow target=ollama-qube
Here is an example, browser-qube is accessing ollama-qube
In the qube that is connecting to Ollama, you can use systemd to automatically initiate the connection at boot.
In /rw/config, create the following two files
ollama@.service
[Unit]
Description=Ollama service
[Service]
ExecStart=qrexec-client-vm '' qubes.ConnectTCP+11434
StandardInput=socket
StandardOutput=inherit
Restart=always
RestartSec=3
ollama.socket
[Unit]
Description=Ollama socket
[Socket]
ListenStream=127.0.0.1:11434
Accept=true
[Install]
WantedBy=sockets.target
Add the following code to /rw/config/rc.local
cp -r /rw/config/ollama* /lib/systemd/system/
systemctl daemon-reload
systemctl start ollama.socket
This code til automatically start the Ollama connection when the system boots.
When the system boots, it binds the local port localhost:11434 to the remote port ollama-qube:11434. To applications running in the qube, it looks like Ollama is running on localhost:11434, and any application that can use Ollama will work out of the box.
You can repeat this for as many qubes as you need, just add them to the policy file, and set up the systemd files.

